Pong From Pixels.
by John Robinson @johnrobinsn
In one of my all-time favorite blog posts, Andrej Karpathy explains how a tiny 130 line Python script can learn to play "pong from pixels". But perhaps the more amazing thing is that the core code he provides knows nothing specific about the game of Pong and can be applied to a large number of different games/problems. Such is the power of reinforcement learning.
Reinforcement learning focuses on how a machine learning model can learn to do complex tasks with nothing more than the ability to observe the environment, along with the ability to take an action within that environment and the ability to eventually get back a penalty or a reward. Karpathy's code uses a simple two layer neural network consisting of fully connected layers. The matrix math and backprop are done just with numpy running on the CPU (no GPU required). It also leverages OpenAI's Gym framework which is a python library wrapper for a large number of simulated games. Gym allows you to capture snapshots of a simulated game environment (ie. the raw pixels from a Pong game at a point in time) and allows you to inject actions (eg. move the paddle up or down) into the game and get back rewards (or penalties) all with just with a few lines of code. Gym is a great testbed for RL tasks, supporting around 60 different Atari games as well as 3D virtual environments.
I don't want to repeat too many detail's from Andrej's post as you should really read that for yourself. But the code linked by his article has become a bit stale having been written for Python 2. I've provided updated code in my github repo to work with Python 3 and I've added some code for Tensorboard logging. I've also included a pretrained model, so that you can demo the model playing even if you'd rather not train the model from scratch yourself.
In Andrej's original article, he describes how given nothing more than the ability to get pixels from a rendered pong game and a reward signal (+1 if a point is won and -1 when a point is lost) that 130 lines of Python code can learn to play pong proficiently.
Here is a brief video of my pretrained model playing. The model is playing on the right-hand side.
Reinforcement learning sounds amazing (and it is in its own way...) so what's the catch?
Well... training takes a helluva long time.
Here is a tensorboard graph showing the training run for the pretained model that I provided. Score is on the y-axis and hours of training is shown on the x-axis.
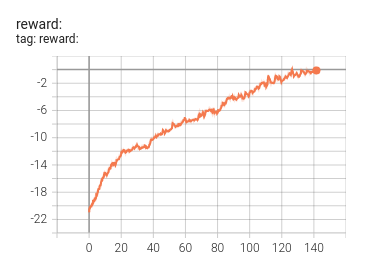
As you can see, it takes a lot of training to converge to reasonable game play. Which shouldn't be too surprising. It's actually sort of surprising that it works at all. It's easy to imagine that something more impressive is happening. The model doesn't know it's playing Pong after all. The model is not learning the physics of the environment or something of a high order nature. All it's getting is an ordered list of numbers representing the pixel values at a given point in time. And the model is expected to figure out how to map patterns within this list of numbers to actions that win more often than they lose. At first those actions are sampled from a random distribution. But as rewards are given for a given state/action pair, the weights in the parameters of the model are nudged along a gradient to encourage actions that led to the reward or nudged to discourage actions that led to a penalty. Given enough iterations, the weights will eventually learn to map input states to winning actions.
If you'd like to learn more about reinforcement learning after reading Karpathy's article, I'd recommend that you read Reinforcement Learning: An Introduction (free pdf) by Richad Sutton.
In an upcoming post, I'll show how to implement something similar in PyTorch which will unlock the ability to train on GPUs and speed up the training a bit. PyTorch will also simplify working with larger and more complex machine learning models.
Share on Twitter | Discuss on Twitter
John Robinson © 2022-2023