Posing Heads with Stable Diffusion
by John Robinson @johnrobinsnThis is an overview of my experiments using an Image Regression Model to guide head position, pose and scale of "headshot"-style images generated by Stable Diffusion.
All with no fine-tuning of the Stable Diffusion model!
In these experiments, I have not done any fine-tuning of the Stable Diffusion model. Rather I'm using my own image regression model (trained on a head pose dataset) to guide Stable Diffusion's image generation at inference time, operating in latent space rather than image space.

Prompt: ‘Photo of a woman’
This is built on top of a technique outlined in Jonathon Whitaker's ground-breaking article, Mid-U Guidance: Fast Classifier Guidance for Latent Diffusion Models. In this article, He describes a new technique for efficiently using an image classifier model to guide Stable Diffusion inference.
Latent diffusion models such as Stable Diffusion make it difficult to use image models for classifier guidance, since they operate internally on a highly compressed image represention (latents). Trying to use a classifier that operates in image space to steer the image generation process, would require tracing gradients not only through the classifier model, but also back through the decoder for the VAE and the upsampling path of Stable Diffusion's UNet making it very memory and compute intensive.
The magic of JohnO's approach is his realization that the Stable Diffusion encoder is a very powerful feature extractor and if there was a way to intercept the feature map from the encoder that this could be used as the backbone of a classifier model that operates in latent space rather than image space.
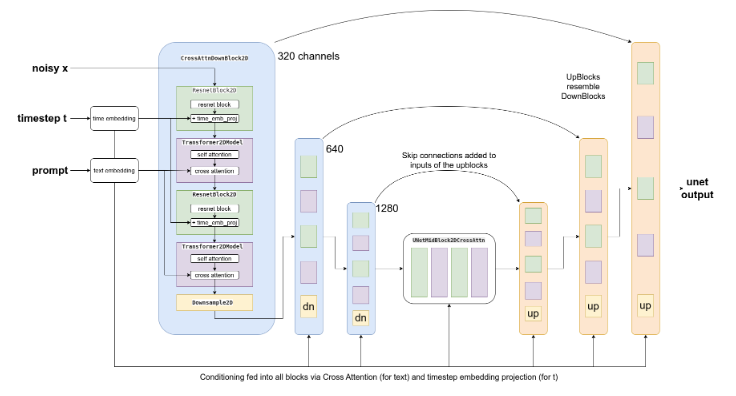
This diagram[1] above illustrates the UNet from Stable Diffusion. The blocks with the blue background show the "encoder" (downsampling network) and the orange blocks show the decoder (upsampling network). The block in the middle is called the mid-block and is the point at which the encoder and decoder meet.
JohnO descibes using a PyTorch hook to intercept the feature map from the mid-block of Stable Diffusions UNet giving us a (1280,8,8) compact but rich feature map upon which to train our custom model.
For my experiments, I built an image regression model that I've trained to predict head position, orientation and scale from input images.
Later I'm able to use this model at Stable Diffusion inference time to specify numeric targets for head position, orientation and scale.
Sample Images #
In these sample images, I’m using my model to steer Stable Diffusion to center the generated headshot and to “pose” the generated image in a given direction not with a text prompt, but by using my model to steer the orientation using numeric targets for pitch, yaw, x, y and scale.
Interpolation in pitch and yaw space with specified centered head position, I can generate a wide variety of head poses.

For demonstration purposes, I'm mapping these numeric pose targets to one of 'left', 'right', 'up', 'down', and 'front'.

Prompt: ‘Photo of a woman’

Prompt: “magazine with a woman on the cover”

Prompt: “photo of a man”

Prompt: “photo of a man”
Afterword #
This is a very rich space to explore and I have a ton of other related research ideas. I used miniai, a new "experimental" machine larning framework from @jeremyphoward to train the model that I described in this article. It's super flexible and its modest size make it a great platform for experimentation.
References
[1] Mid-U Guidance: Fast Classifier Guidance for Latent Diffusion Models by Jonathon Whitaker 2023
For all commercial inquiries, please contact sales@liquidthought.com
Share on Twitter | Discuss on Twitter
John Robinson © 2022-2025